Most Schema case studies show off what worked. This one shows what didn’t — and why that matters more than people think.
Here’s what happened when I deployed Dataset Schema to MedicareWire.com — without fully aligning it with visible citations and structured content blocks:
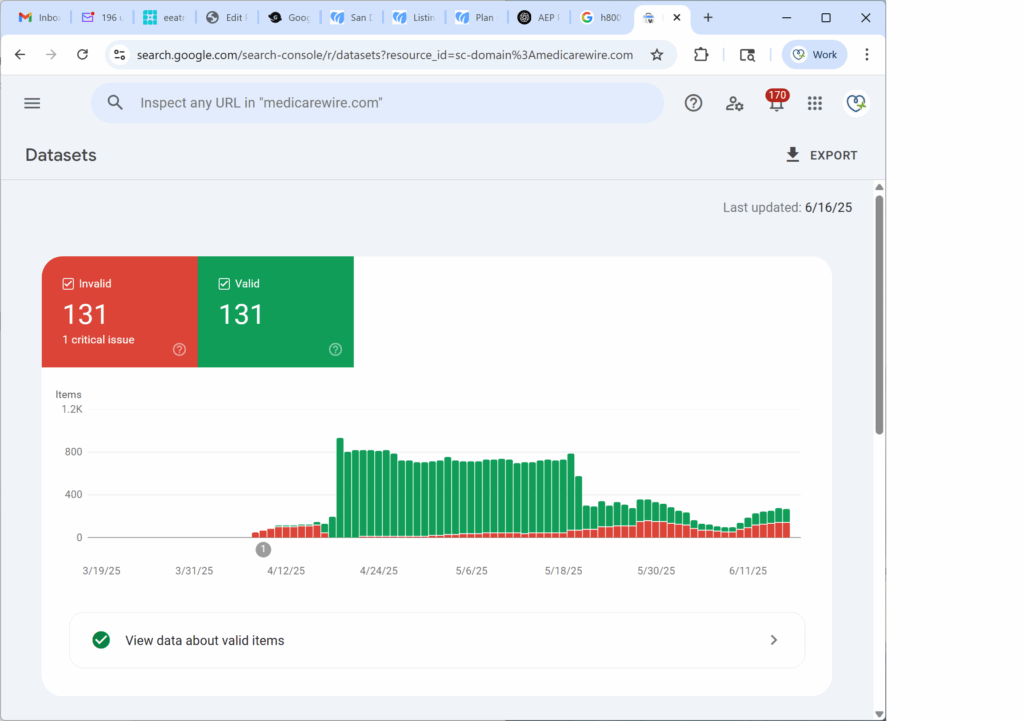
What you’re seeing here is a correction.
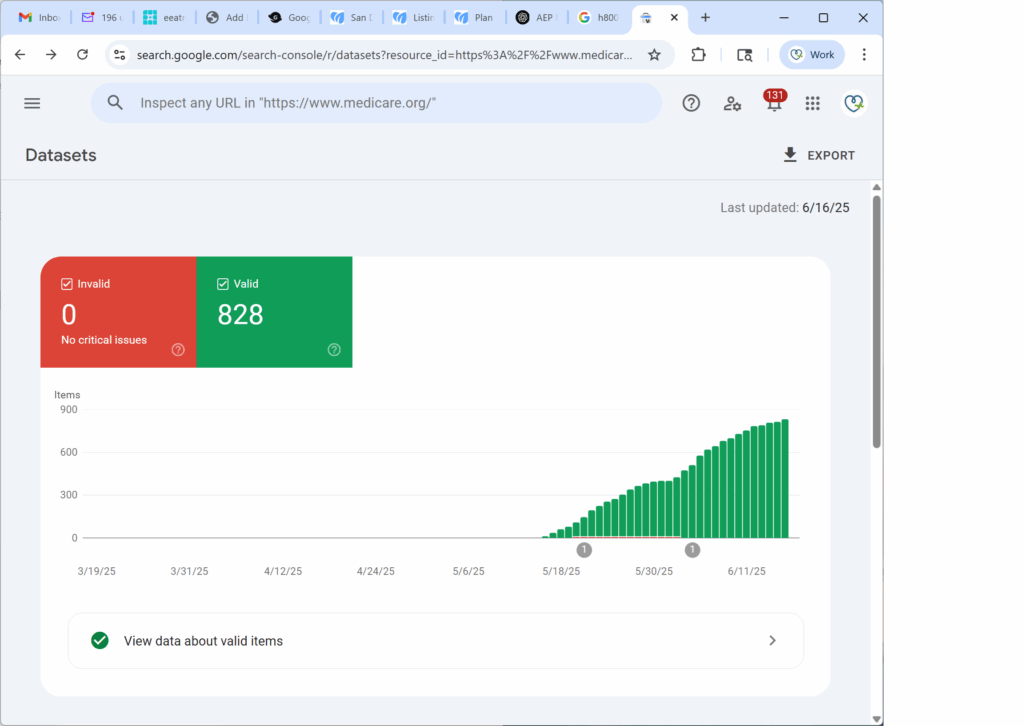
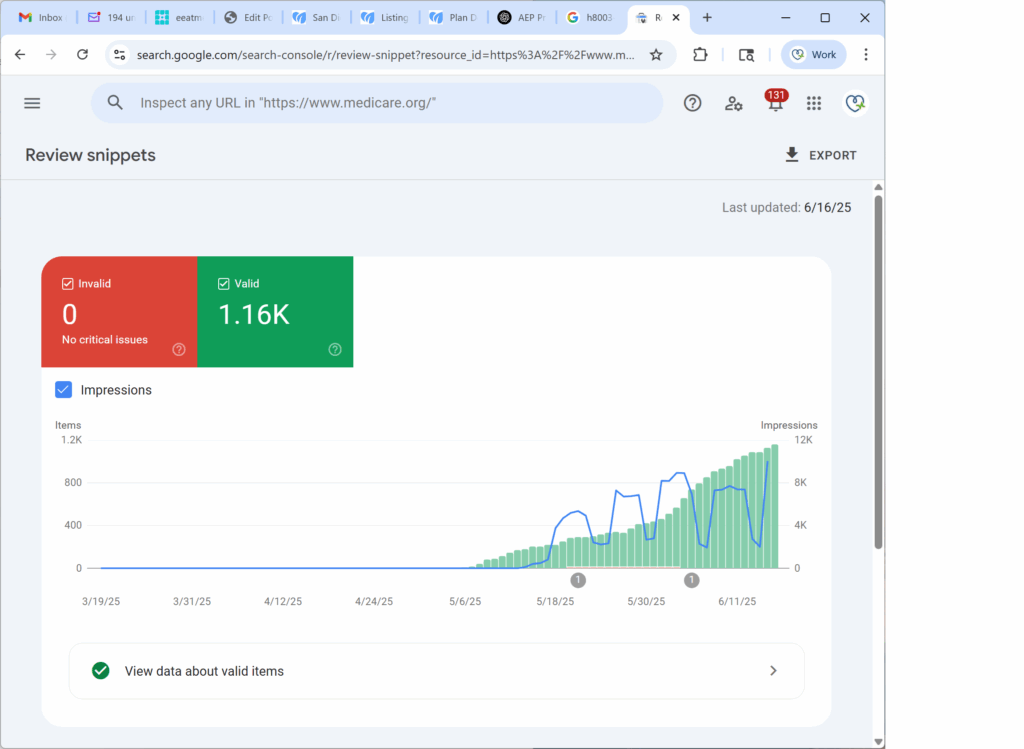
An early spike in valid datasets… followed by a sharp decline, a rising stack of invalid items, and a steady loss of Schema trust.
Why am I showing this?
It comes down to this one fact. You can’t learn what works until you discover what doesn’t work. So I have been using my MedicareWire site as a punching bag.
To be fair, Google relegated MedicareWire to the trash heap anyway. It couldn’t fall much lower. So, using it as a test platform makes perfect sense. And it has been teaching me a lot.
The Mistake: Schema Without Trust
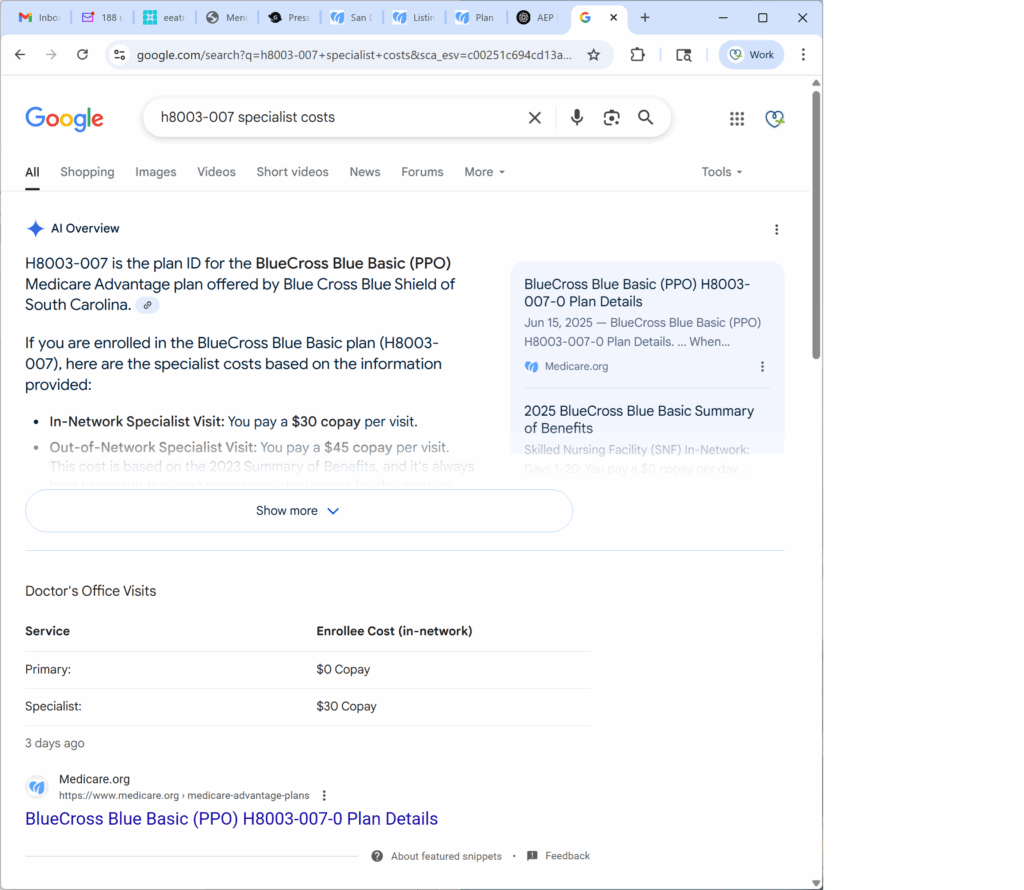
The initial Dataset Schema was technically valid. It passed markup checks and included CMS.gov source URLs.
But it lacked supporting structure in the page body.
Specifically, it had:
- No linking of data points to their sources
- No human-readable citations visible on the page
- No semantic structure around data values
In short, it was Schema… without a trust layer. Google’s response was to call bullshit on what I was publishing.
How Google Responded
At first, it accepted the markup — 131 valid items were indexed. But over time, as the algorithm deeply evaluated the content and schema, it found a misalignment and started pulling back.
The result: 131 invalid items, and a stall in dataset visibility.
Google didn’t just stop crawling. It re-evaluated the trust signal — and demoted it.
The Lesson: Trust Must Be Visible and Verifiable
You can’t publish Dataset Schema in a vacuum. If Google can’t see the proof — it stops believing the markup.
That’s why TrustStacker now enforces:
- Inline TrustTags™ for every key fact
- Matching Dataset Schema with identical human-readable citations
- Semantic layout (TrustBlocks) to deliver content Google and AI systems can understand
This Proof Drop isn’t a loss. It’s a warning — and a reminder that trust must be engineered across every layer.
— David W. Bynon